Today’s challenge
Visual data can come in a variety of different visual domains (visual styles). Real photos are captured by consumer cameras and posted on social networks and web storage, product photos under studio lighting and on clean uniform background appear on online shopping websites, sketches and wireframe diagrams appear in technical documentation, clipart and doodle images appear on slideshows, night time or weather condition change visual appearance, and more and more to the infinite variety. Modern AI relies mostly on various forms of representation learning realized by deep networks in order to perform various downstream tasks (e.g. classification, detection, segmentation, retrieval, etc.). For supporting semantic cross-domain alignment (so instances of the same semantic class land in close locations in the representation feature space), modern approaches commonly require massive investments in annotation (supervision) in some of the domains of interest (source domains) and commonly have difficulties to generalize to unseen (during training) domains (aka the domain generalization problem).
MIT-IBM innovation
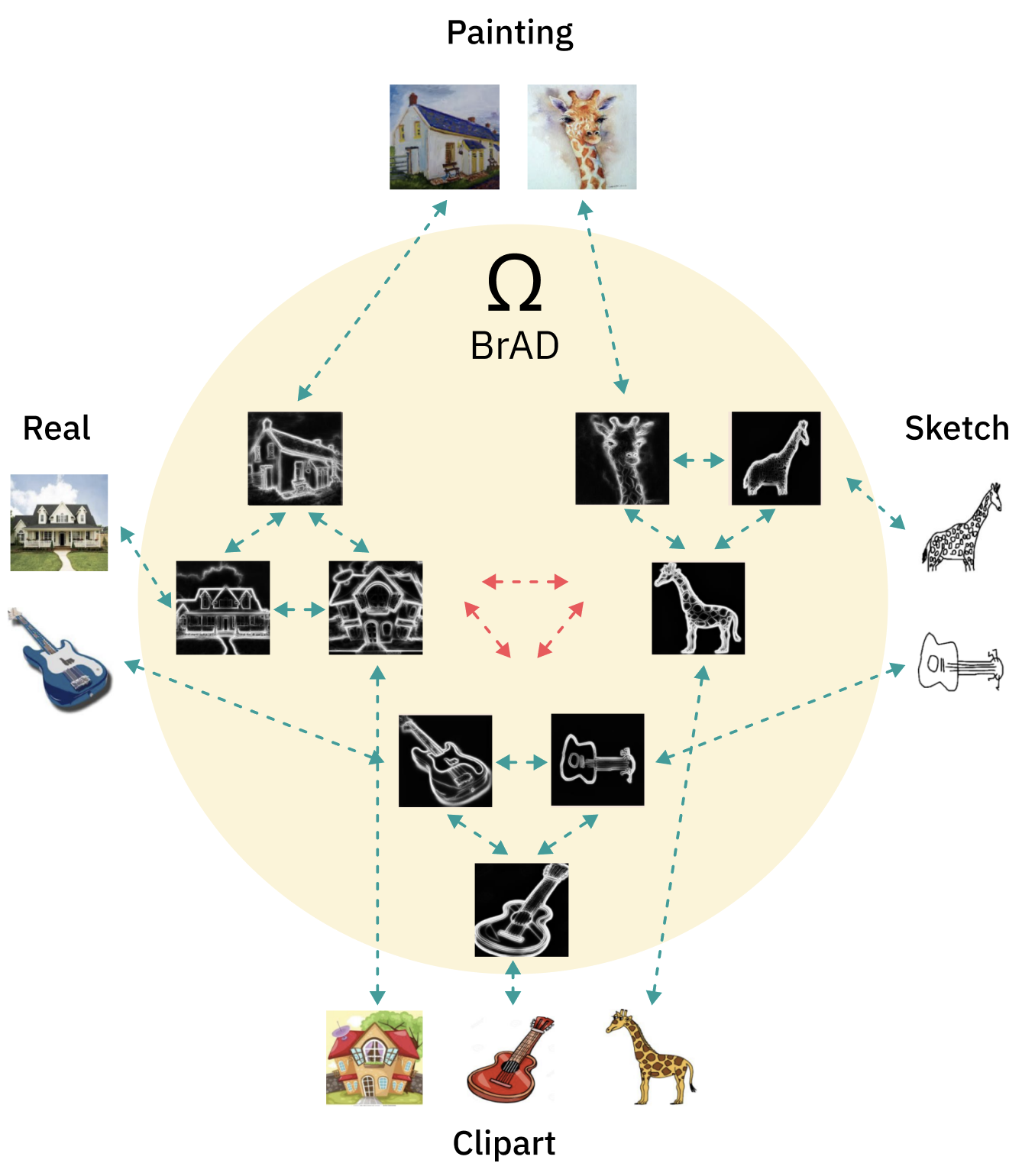
Develop an approach for completely self-supervised (and hence very practical) cross-domain representation learning that is able to semantically align multiple unlabelled domains simultaneously using a single model (compared to the common somewhat inefficient UDA approach of pairwise, fully-source-supervised, domain mapping). Our approach learns (without labels) an edges-regularized auxiliary (bridge) visual domain, for visually mapping all the domains to a common visual space. This in turn facilitates completely self supervised contrastive representation learning achieving great results not only in the original (training) domains of interest, but also in domain generalization mode - that is on unseen (test-only) visual domains.